Authors: Siyu Chen, Yexiaolu He, Jinxin Xiao, Celine Zhao
Introduction
Imagine stepping into a world where virtual characters, known as generative agents, aren’t just scripted entities but beings with the capacity to remember, learn, act, and make decisions as dynamically as any human would. This isn’t just a flight of fancy; it’s the core of what we’re exploring here.
We’ve built our work based on the paper Generative Agents: Interactive Simulacra of Human Behavior, where it successfully built a virtual town populated by 25 agents and they interact with each other just like we do. Here, agents are not just animated by code; they’re enlivened dynamically by their own unique experiences thanks to the power of ChatGPT large language model(LLM).
However, the high cost associated with this model made it imperative for us to seek more sustainable yet equally potent alternatives, leading us to transition to LLaMA-2, a free, efficient, and well-performed LLM to ChatGPT model.
Cost isn’t the only frontier we’re tackling, we face the intriguing dilemma of memory. The original work indicated that agents sometimes fabricate memories or assimilate inaccurate information, a byproduct of relying solely on LLMs for their knowledge base. To improve memory consistency and enhance our agents’ ability to interact with their world as humans do, we devised two distinct memory structures. The default memory architecture is just a list of strings that contains daily events, actions, and summaries that agents draw from. Another framework is Retrieval Augmented Generation (RAG), which doesn’t just store information; it intelligently retrieves and filters data from an extensive external knowledge base. RAG ensures our agents are grounded in reality, basing their decisions and interactions on the most accurate and current information available.
We’re not just building a simulated environment; we’re crafting a micro-society where each interaction is as meaningful and real as those in the human world. As we continue to develop these memory structures, we invite you to follow our journey and witness the evolution of AI interactions in AI Town where every agent has a story grounded in reality.
Methods
Our methodology encompasses the design, implementation, and comparative analysis of two distinct approaches to memory architecture in AI agents: the traditional memory structure utilized by LLaMA-2 and the innovative Retrieval-Augmented Generation (RAG) structure powered by Llama Index. Our objective is to assess how these differing memory architectures impact learning efficiency, memory accuracy, and overall performance of generative agents within a simulated interactive environment.
LLaMA-2 with conventional memory architecture
LLaMA-2 comes with a standard memory setup, where the model’s internal state acts as the sole repository for information retention and retrieval, which mimics a traditional language model approach. In this architecture, the generative agent relies on its pre-trained knowledge and the information acquired during the simulation, where the memory is static. Agents use this memory model to generate responses and make decisions based on the static knowledge embedded within the model’s parameters and context provided by the simulation environment.
Llama Index for RAG
Llama Index for RAG introduces a dynamic external memory component to the conventional LLaMA-2 setup. The RAG structure enables the model to query an extensive external knowledge base in real-time, augmenting the agent’s responses with information retrieved from the external database. The RAG model interacts with the Llama Index, an extensive database of information that can be contextually searched during an agent’s decision-making process. The approach brings inclusion for up-to-date and relevant data information that may not be presented in the original training set. Agents equipped with the RAG memory structure can access a wider range of information beyond their internal knowledge base, which enables more nuanced and informed interaction as agents can pull relevant data from the Llama Index to generate responses and make decisions.
Results
Memory Consistency
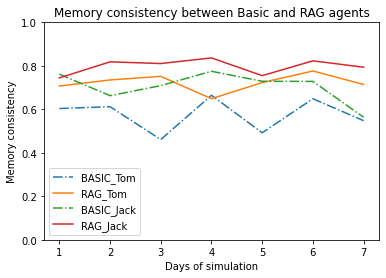
In our simulation, we compared the memory consistency of agents with basic memory structure (memory that is a list) and agents implemented with RAG. Over the course of seven days, agents ‘Tom’ and ‘Jack’ show us how well they can stick to their daily plans.
From the plot we discovered that: Agents with RAG memory(dashed line) has higher memory consistency, suggesting that they stick closer to their daily plans, which indicates that RAG memory structures may offer more reliable performance.
Check out the chart below to see the daily memory consistency levels of each agent. Higher values indicate better consistency and alignment with planned actions.
Difference in Plans
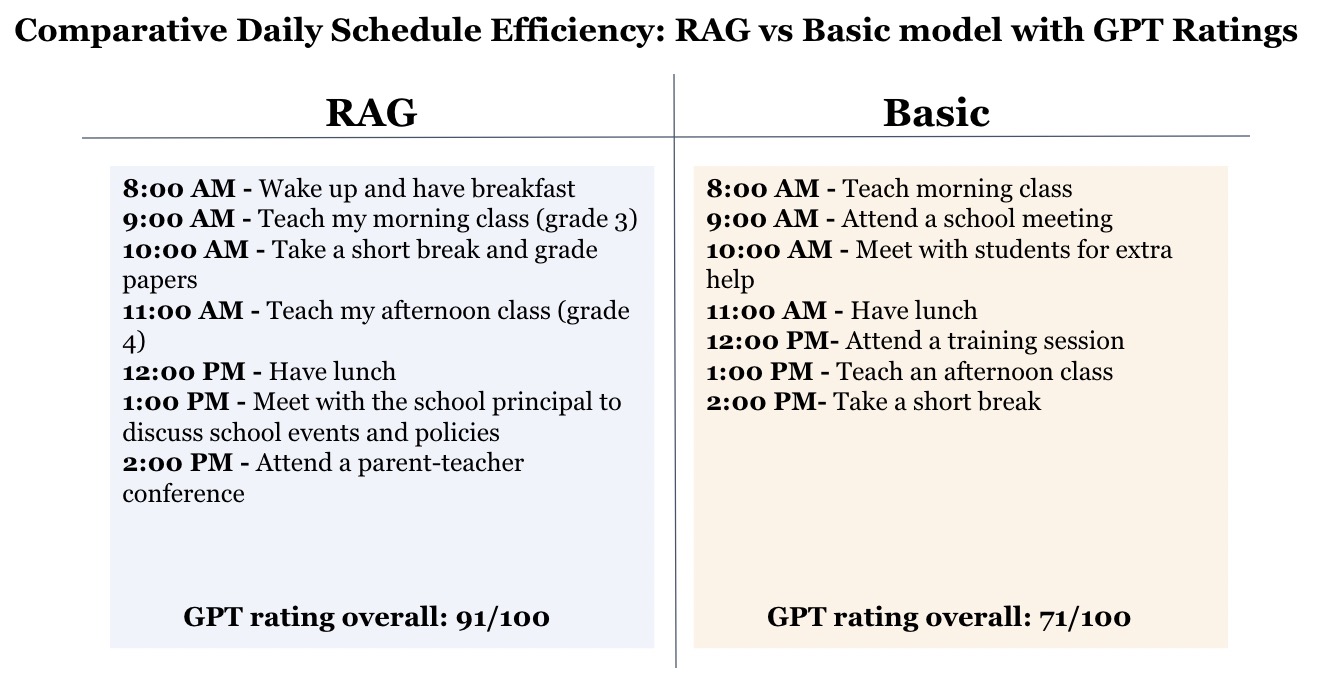
Our generative agents are scored on their planning abilities, and the results highlight the sophisticated capabilities of agents with RAG structure.
ChatGPT-4 Overall Evaluation Score:
- Basic Agent: 71/100, reflecting decent planning.
- RAG Agent: 91/100, reflecting strategic and adaptable planning.
When we introduced additional details about our agents’ preferences and goals, the RAG system demonstrated its adaptability. For instance, when we mentioned that Tom, our dedicated teacher agent, wanted to explore the world and consider a career change, the RAG agent adjusted Tom’s daily schedule to include actions like discussing a career break planning a trip, and writing farewell letters to students.
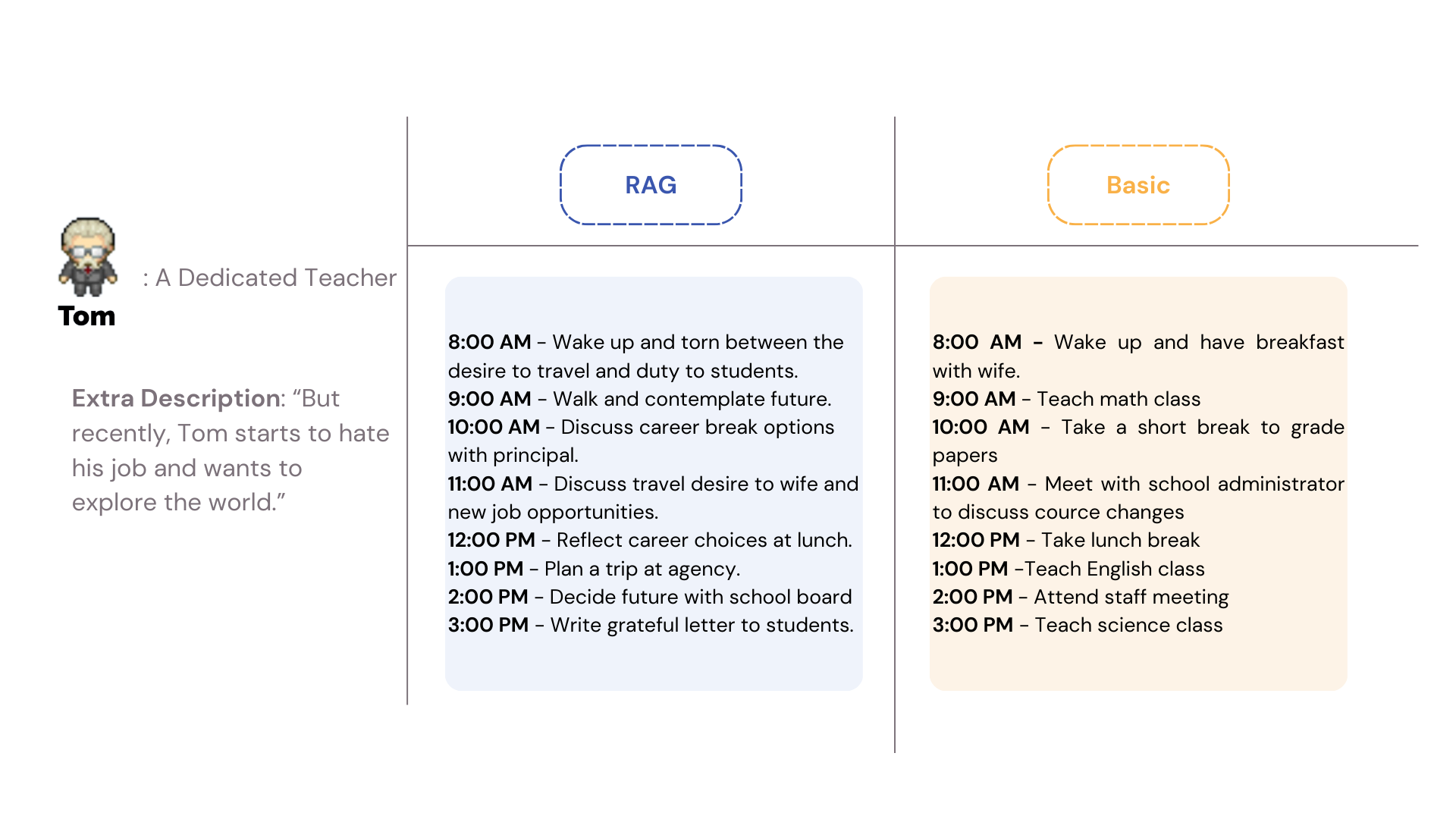
The contrasting scores and the RAG’s responsiveness to extra description underline the potential of RAG, in creating agents that can think ahead and adjust to new circumstances, much like humans do. This insightful comparison reinforces the value of sophisticated RAG memory structures in developing agents that are not just reactive, but truly responsive to their environment.
Conclusion
The comparative analysis conducted in our simulated environment, agent village, provides compelling evidence of the efficacy of Retrieval-Augmented Generation (RAG) as a superior memory structure for generative agents throughout a three-day simulation, where both RAG and standard model ran. The RAG-equipped agents not only sustained a steady memory consistency but also showed an upward trend, suggesting a learning curve where the agents improved their memory coherence over time. Conversely, basic agents experienced a gradual decline in memory consistency. This outcome highlights the limitations of a static knowledge base in dynamic scenarios. In conclusion, these findings underscore the potential of RAG structures in enhancing the reliability of interactions in AI-driven simulations, virtual environments, and natural language processing.